Taehyun ChoAI Researcher • Reinforcement Learning & Decision TheoryStarting August 2026, I will join the Vector Institute (as a Vector Distinguished Postdoctoral Fellow) and the Fields Institute. At both, my host will be Prof. Tim G. J. Rudner of the University of Toronto. I am currently a postdoctoral fellow at the Cognitive Machine Learning Laboratory, Seoul National University, where I received my Ph.D. under Prof. Jungwoo Lee. I hold a B.S. in Mathematics from Korea University. E-mail: talium@cml.snu.ac.kr GitHub / Google Scholar / LinkedIn / CV
|


|
Personal Interest |
|
Strategic Games: Behavioral Economics and Cognitive Science: Philosophy: |
Research Interest |
|
My research focuses on sequential decision-making under uncertainty, particularly in the context of human feedback. I have extensively studied distributional reinforcement learning (DistRL), reinforcement learning from human feedback (RLHF), and regret analysis, aiming to bridge theory and practice. My long-term goal is to build human-aligned, socially aware agents — systems that reason about people and act on their preferences, values, and decisions. I draw inspiration from how humans make decisions. By seeking to understand the cognitive mechanisms underlying human choice and mathematically modeling the structure that governs interaction, I aim to develop both theoretical insights and practical algorithms for robust decision-making under uncertainty. Currently, I’m interested in reasoning LLM agents and regret-based decision theory. |
Recent News |
| July 2026 — I gave a talk at the Cortiq Summit on A Regret Minimization Framework on Preference Learning in Large Language Models, awarded by SK Inc. AX. |
| June 2026 — I will join the Vector Institute as a Vector Distinguished Postdoctoral Fellow, starting August 2026. |
| May 2026 — I received the INMC Young Researcher Award from the Institute of New Media and Communications, Seoul National University. |
| May 2026 — I received the Gold Reviewer Award (Top 25%) at ICML 2026. |
| May 2026 — Our paper A Regret Minimization Framework on Preference Learning in Large Language Models was accepted at ICML 2026 as a Spotlight (Top 2.2%). |
| May 2026 — Our paper MVP-LAM: Learning Action-Centric Latent Action via Cross-Viewpoint Reconstruction was accepted at ICML 2026. |
| Apr 2026 — I gave a Vector Visitor Research Talk at the Vector Institute on Rethinking Human Feedback: A Regret Minimization Perspective on Preference Learning. |
| Apr 2026 — I gave a talk at the SNU AI Summit on Policy-labeled Preference Learning: Is Preference Enough for RLHF? |
| Feb 2026 — I was selected for the Fields Institute - Principles of Intelligence Postdoctoral Fellowship. |
| Feb 2026 — I was selected for the Sejong Science Fellowship for the project Distributional Regret Analysis for Human-Aligned Interactive Agentic AI under High Uncertainty. |
| Feb 2026 — I received my Ph.D. in Electrical and Computer Engineering at Seoul National University and was honored with the Distinguished Dissertation Award. |
Dissertation |

|
A Distributional Perspective on Human-Aligned Decision Making under UncertaintyTaehyun Cho Department of Electrical and Computer Engineering, Seoul National University Distinguished Dissertation Award paper / |
Preprints |
|
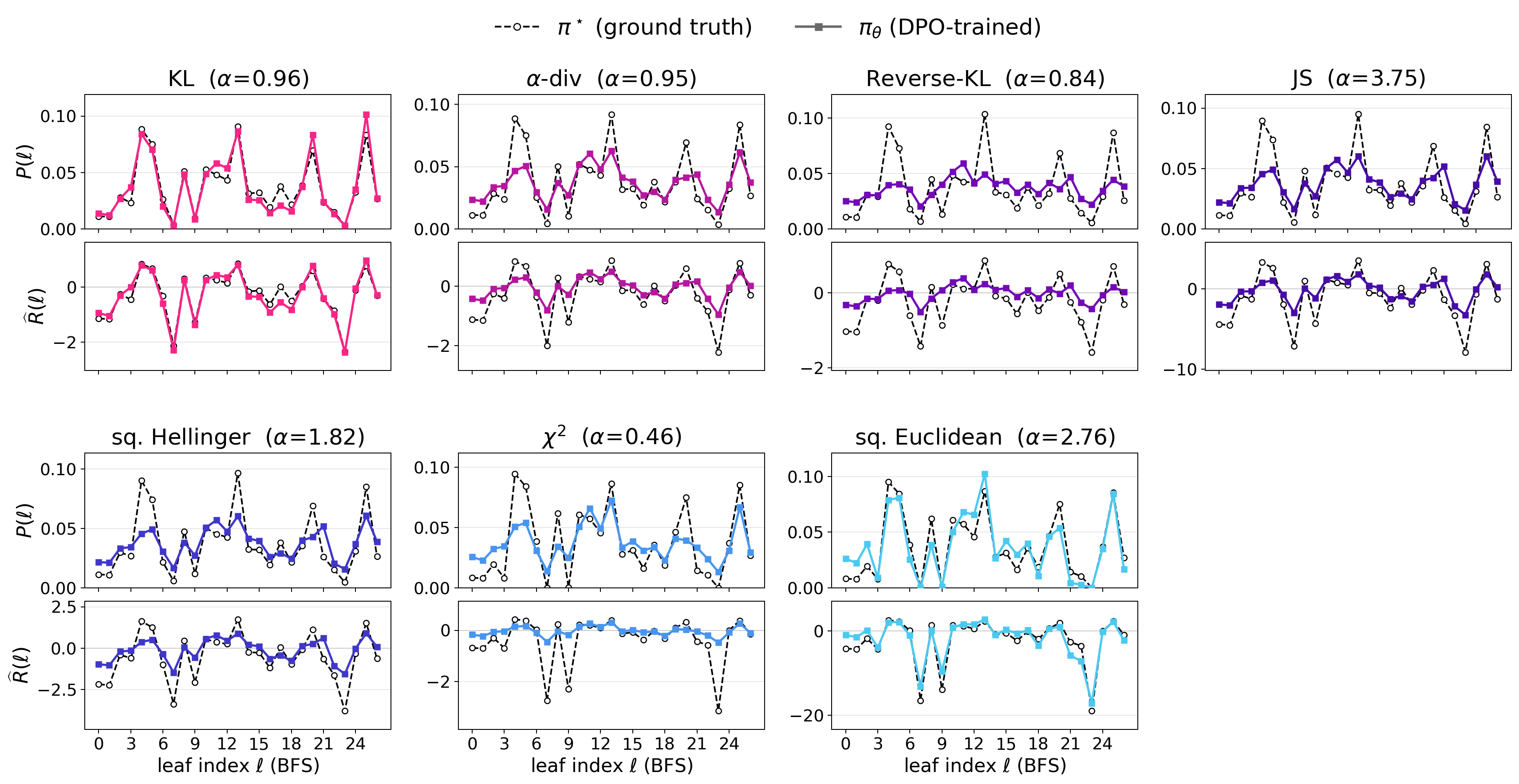
The Unique Off-policy Admissibility of KL Divergence in Direct Preference OptimizationTaehyun Cho Work In Progress |
|
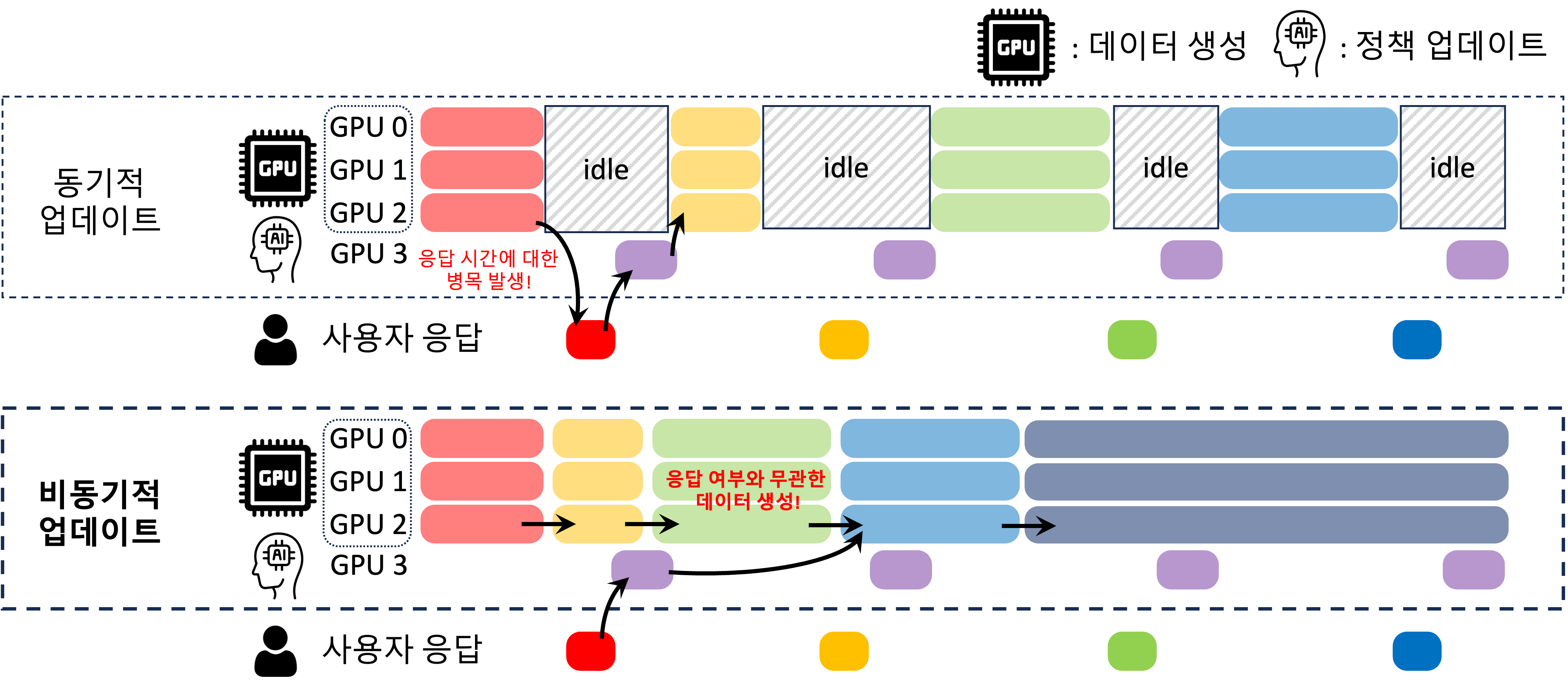
Off-policy Direct Preference Optimization with Monotonic Improvement GuaranteeSeungyub Han*, Taehyun Cho*, Seokhun Ju, Dohyeong Kim, Kyungjae Lee, Jungwoo Lee Work In Progress |

|
An Axiomatization of Process Score Model: Your Process-level Feedback is Not a RewardTaehyun Cho, Suhwan Kim, Seungyub Han, Seokhun Ju, Dohyeong Kim, Kyungjae Lee, Jungwoo Lee Work In Progress |
|
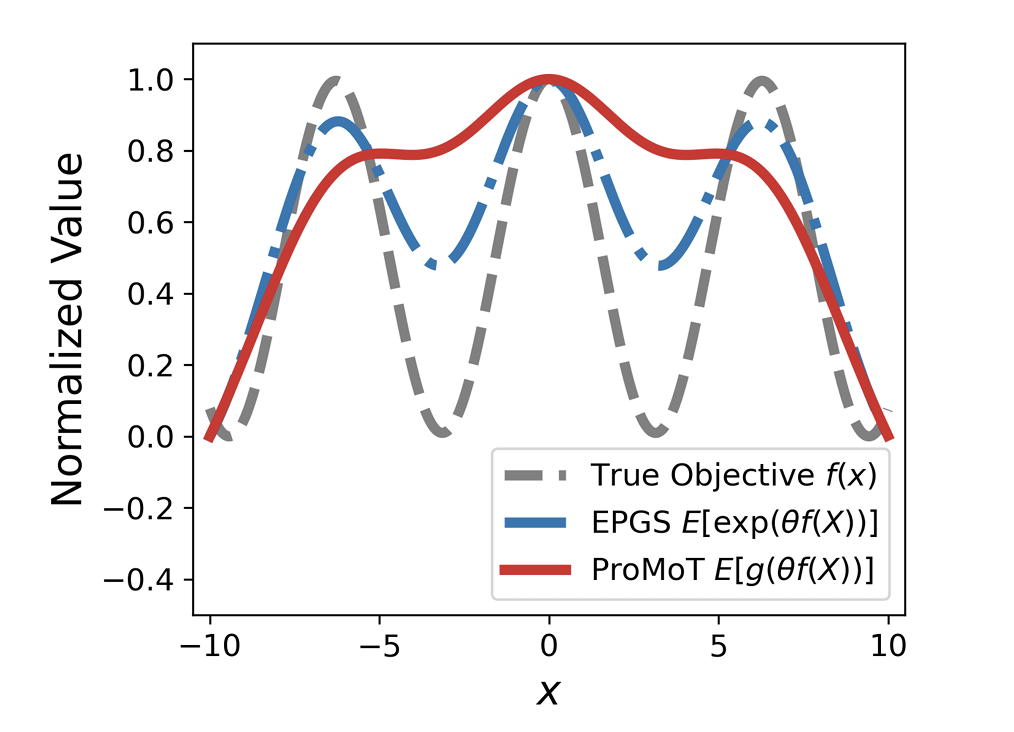
Probabilistic Smoothing with Ratio-Monotone Transforms for Global OptimizationKukyoung Jang, Taehyun Cho, Junrui Zhang, Ping Xu, Kyungjae Lee Work In Progress |
|
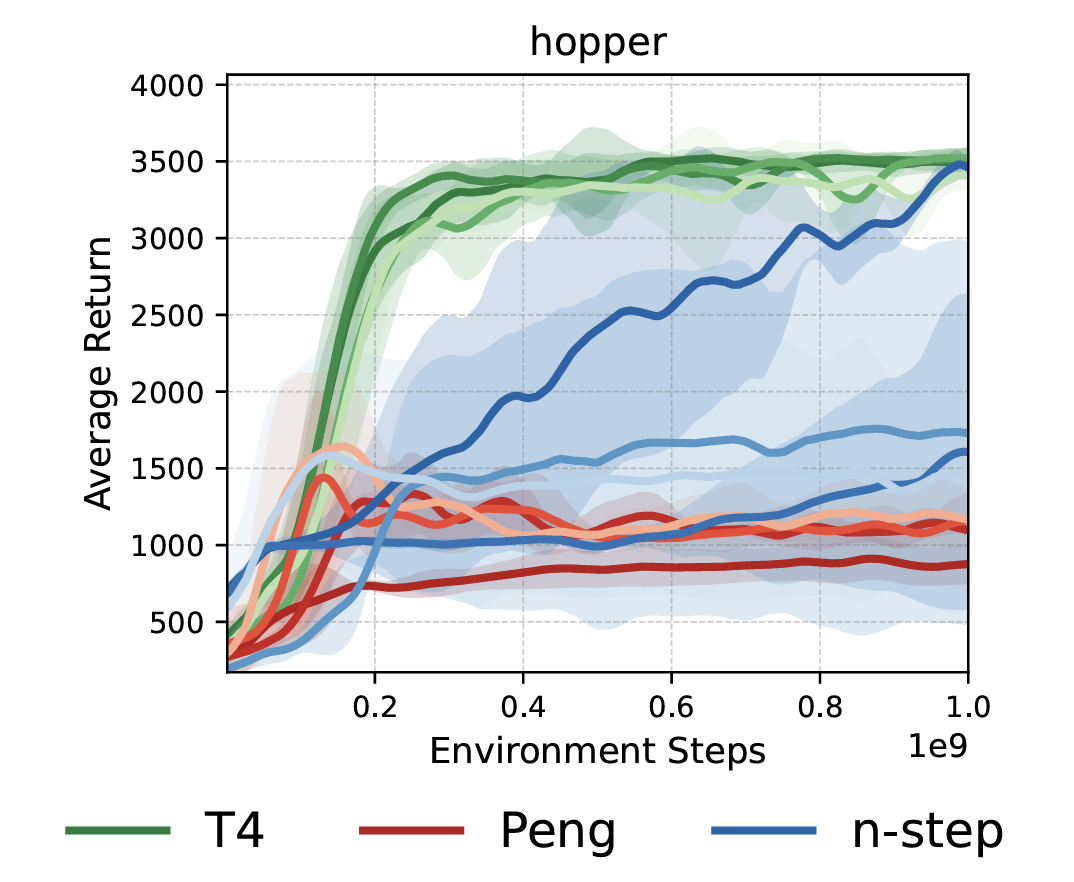
When to Truncate Traces: Stochastic Truncation for Multi-Step Off-Policy RLSeungyub Han, Taehyun Cho, Dohyeong Kim, Kyungjae Lee, Jungwoo Lee Work In Progress |
International Conference |
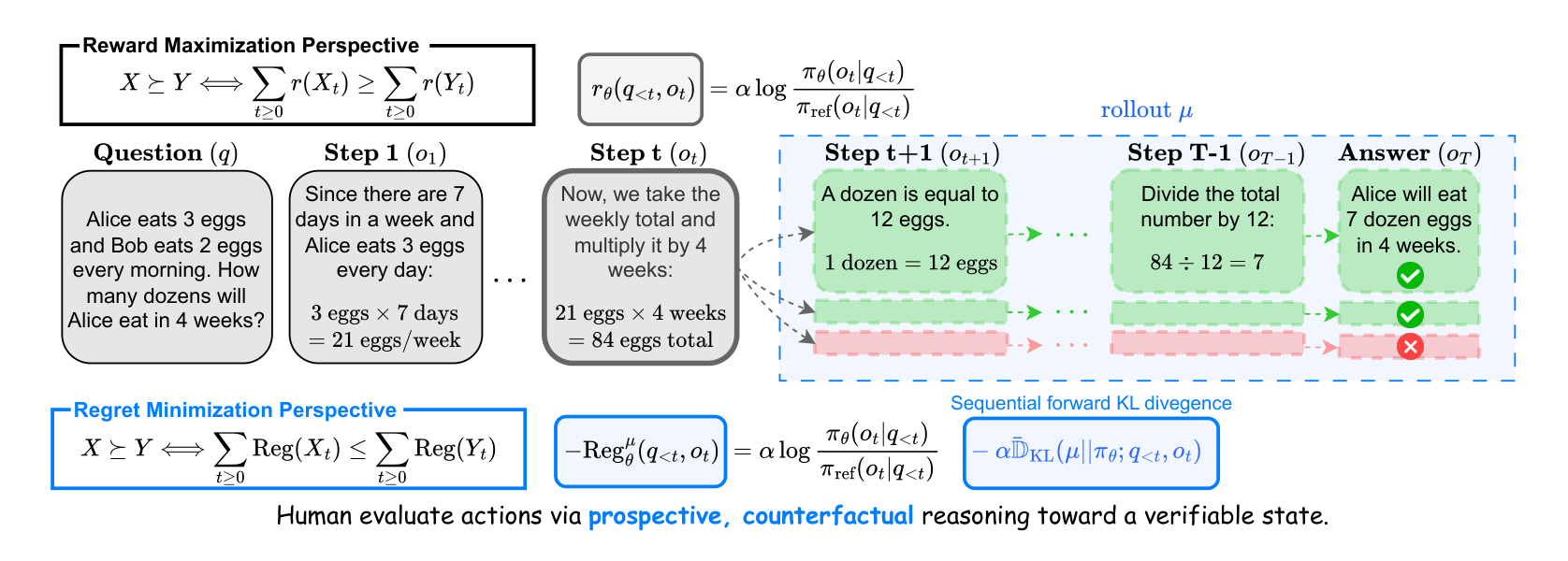
|
A Regret Minimization Framework on Preference Learning in Large Language ModelsSuhwan Kim*, Taehyun Cho*, Geonhyeong Kim, Yujin Kim, Youngsoo Jang, Moontae Lee, Jungwoo Lee ICML 2026 Spotlight (Top 2.2%) paper / project page / slides / |
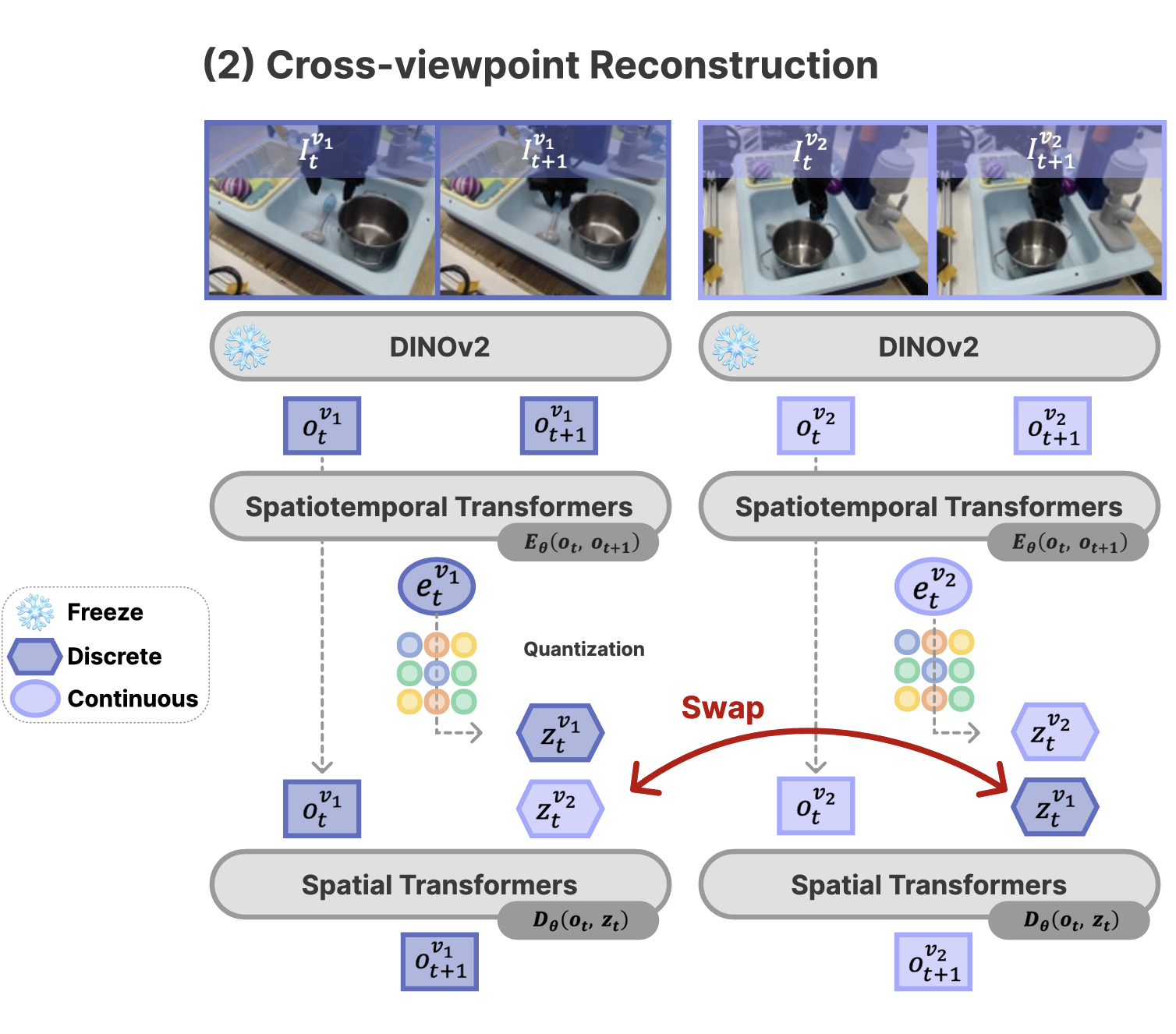
|
MVP-LAM: Learning Action-Centric Latent Action via Cross-Viewpoint ReconstructionJung Min Lee, Dohyeok Lee, Seokhun Ju, Taehyun Cho, Jin Woo Koo, Li Zhao, Sangwoo Hong, Jungwoo Lee ICML 2026 paper / project page / |
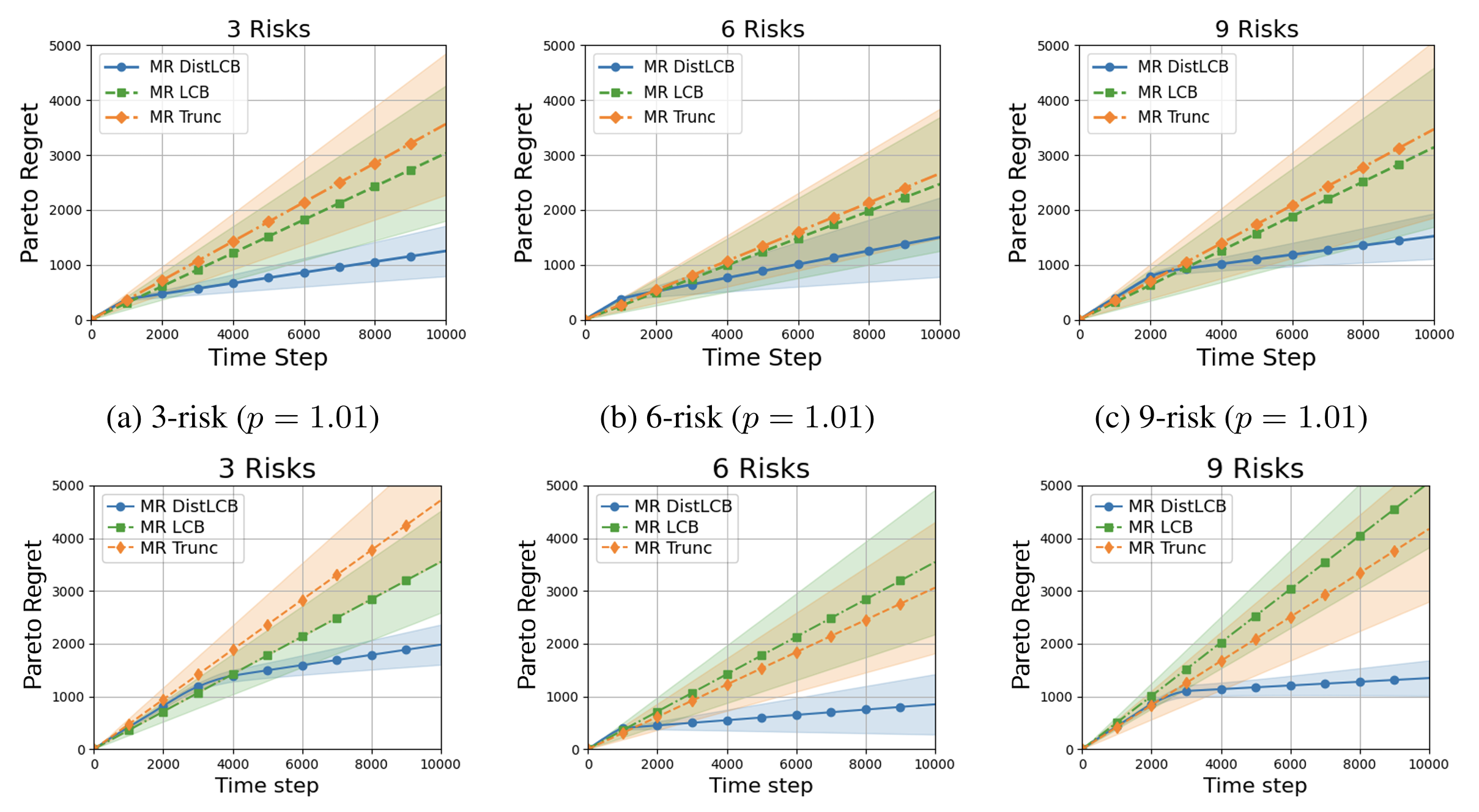
|
Pareto Optimal Risk-Agnostic Distributional Bandits with Heavy-Tail RewardsKyungjae Lee, Dohyeong Kim, Taehyun Cho, Chaeyeon Kim, Yunkyung Ko, Seungyub Han, Seokhun Ju, Dohyeok Lee, Sungbin Lim NeurIPS 2025 paper / |
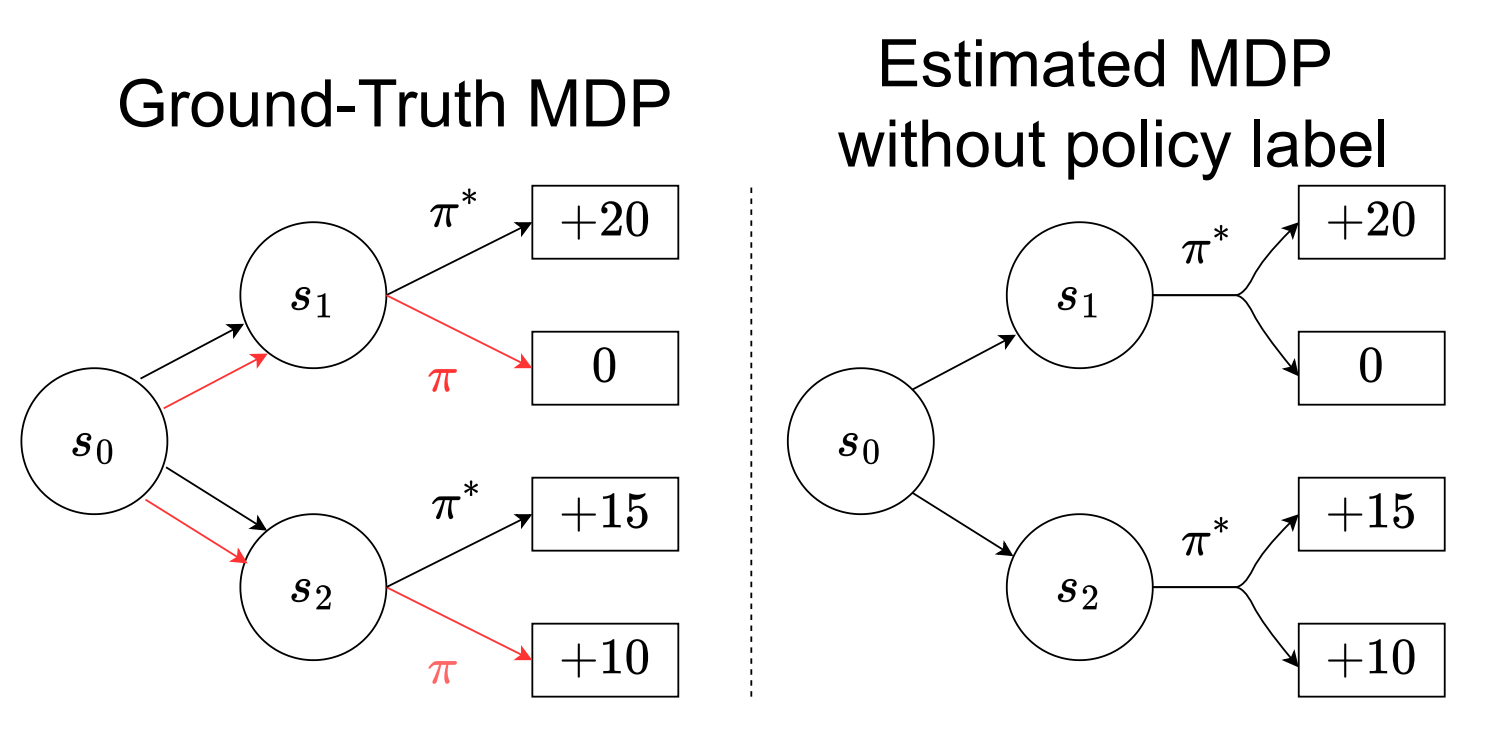
|
Policy-labeled Preference Learning: Is Preference Enough for RLHF?Taehyun Cho*, Seokhun Ju*, Seungyub Han, Dohyeong Kim, Kyungjae Lee, Jungwoo Lee ICML 2025 Spotlight (Top 2.6%) paper / arxiv / |

|
Bellman Unbiasedness: Toward Provably Efficient Distributional Reinforcement Learning with General Value Function ApproximationTaehyun Cho, Seungyub Han, Kyungjae Lee, Seokhun Ju, Dohyeong Kim, Jungwoo Lee ICML 2025 paper / arxiv / |
|
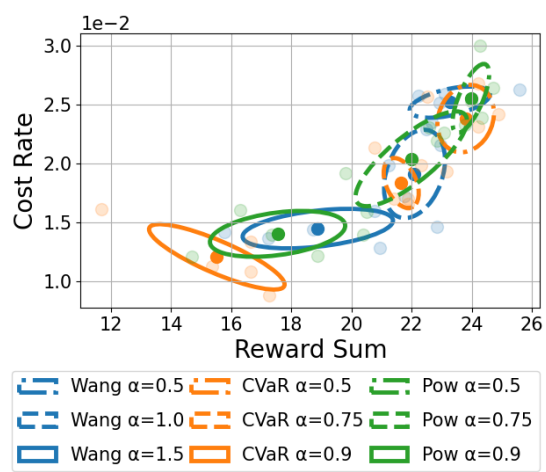
Spectral-Risk Safe Reinforcement Learning with Convergence GuaranteesDohyeong Kim, Taehyun Cho, Seungyub Han, Hojun Chung, Kyungjae Lee, Songhwai Oh NeurIPS 2024 paper / arxiv / |

|
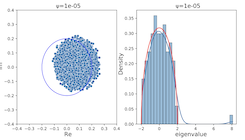
Pitfall of Optimism: Distributional Reinforcement Learning by Randomizing Risk CriterionTaehyun Cho, Seungyub Han, Heesoo Lee, Kyungjae Lee, Jungwoo Lee NeurIPS 2023 paper / arxiv / |
|
SPQR: Controlling Q-ensemble Independence with Spiked Random Model for Reinforcement LearningDohyeok Lee, Seungyub Han, Taehyun Cho, Jungwoo Lee NeurIPS 2023 paper / arxiv / code / |
|
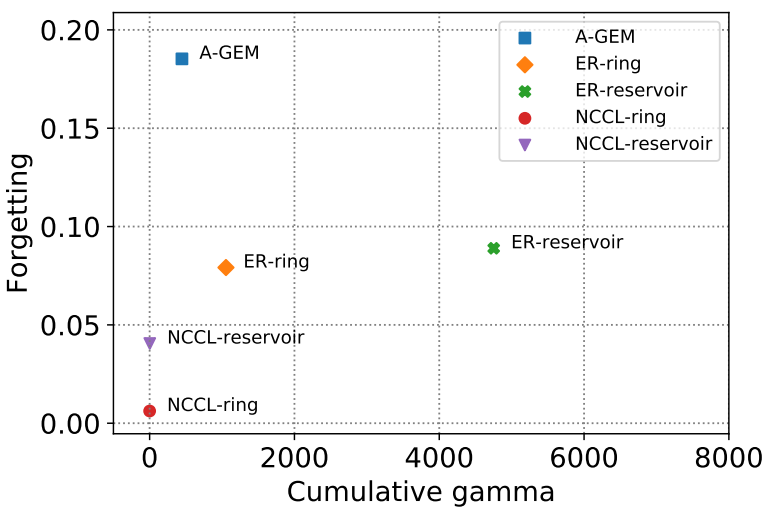
On the Convergence of Continual Learning with Adaptive MethodsSeungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee UAI 2023 paper / arxiv / |
|
Adaptive Methods for Nonconvex Continual LearningSeungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee NeurIPS 2022 Optimization for Machine Learning Workshop paper / |
|
Perturbed Quantile Regression for Distributional Reinforcement LearningTaehyun Cho, Seungyub Han, Heesoo Lee, Kyungjae Lee, Jungwoo Lee NeurIPS 2022 Deep RL Workshop paper / |
|
Chebyshev polynomial codes: Task entanglement-based coding for distributed matrix multiplicationSangwoo Hong, Heecheol Yang, Youngseok Yoon, Taehyun Cho, Jungwoo Lee ICML 2021 paper / arxiv / |
International Journal |
|
Learning Graph Based Individual Intrinsic Reward For Multi-Agent Reinforcement LearningSeokhun Ju, Seungyub Han, Taehyun Cho, Jungwoo Lee, Taeyoung Lee, Minkyoung Kim, Jinho Ahn ICT Express paper / |
|
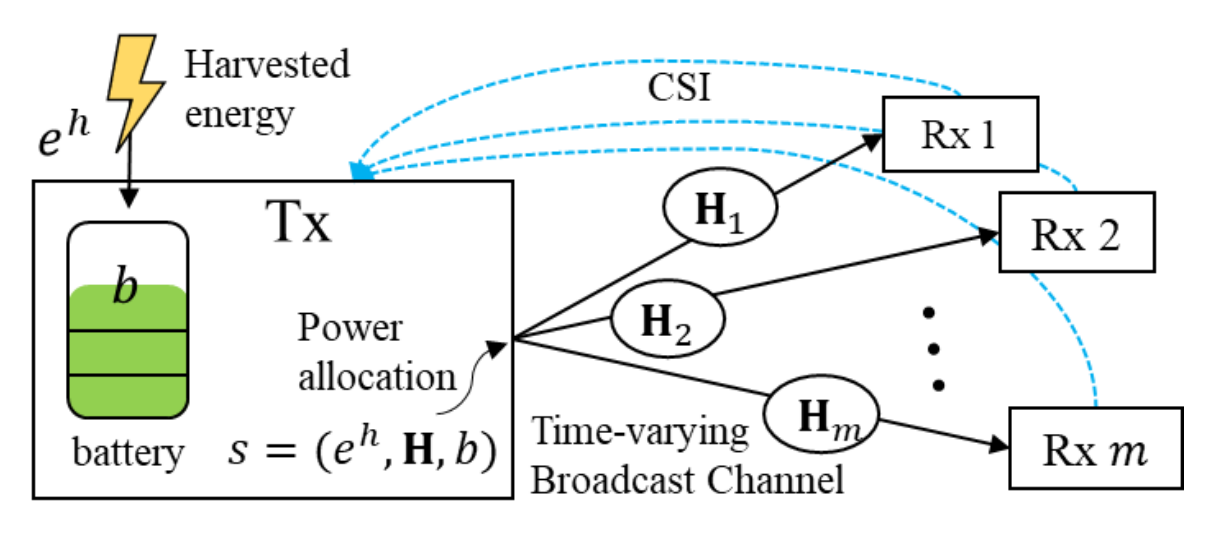
Optimized shallow neural networks for sum-rate maximization in energy harvesting downlink multiuser NOMA systemsHaesung Kim, Taehyun Cho, Jungwoo Lee, Wongae Shin, H Vincent Poor IEEE Journal on Selected Areas in Communications paper / arxiv / |
|
An Efficient Neural Network Architecture for Rate Maximization in Energy Harvesting Downlink ChannelsHaesung Kim, Taehyun Cho, Jungwoo Lee, Wonjae Shin, H Vincent Poor 2020 IEEE International Symposium on Information Theory (ISIT) paper / arxiv / |
Research Projects |

|
Fields Institute - Principles of Intelligence Postdoctoral FellowshipFunded by Fields Institute ( 2026.08 - 2027.08 ) |

|
Sejong Science FellowshipDistributional Regret Analysis for Human-Aligned Interactive Agentic AI under High Uncertainty Funded by National Research Foundation of Korea ( 2026.03 - 2031.02 ) |
Education & Research Experience |
|
|
Vector InstituteVector Distinguished Postdoctoral Fellow 2026.08 - 2027.08 · Toronto, Canada |

|
Fields InstitutePrinciples of Intelligence Postdoctoral Fellow 2026.08 - 2027.08 · Toronto, Canada |

|
LG AI ResearchResearch Intern, Superintelligence Lab 2024.12 - 2025.05 |

|
Seoul National UniversityPh.D./M.S. in Electrical and Computer Engineering 2020.03 - 2026.02 |

|
Korea UniversityB.S. in Mathematics 2013.03 - 2020.02 |
Awards & Honors |
|
Aug 2026 – Aug 2027 — Vector Distinguished Postdoctoral Fellowship
Vector Institute |
|
May 2026 — INMC Young Researcher Award
Institute of New Media and Communications (INMC) |
|
May 2026 — Gold Reviewer Award (Top 25%)
International Conference on Machine Learning (ICML) |
|
Mar 2026 — Principles of Intelligence Postdoctoral Fellowship
Fields Institute |
|
Mar 2026 – Feb 2031 — Sejong Science Fellowship
National Research Foundation of Korea (NRF) |
|
Feb 2026 — Distinguished Dissertation Award
Seoul National University (SNU) |
|
Jan 2023 — Certificate of Commendation
Center for Applied Research in Artificial Intelligence (CARAI) |
|
Mar 2020 – Feb 2026 — Brain Korea 21 Plus Scholarship
Seoul National University (SNU) |
Talks |
|
Jul 2026 — Cortiq Summit, Seoul COEX
A Regret Minimization Framework on Preference Learning in Large Language Models |
|
Apr 2026 — Vector Visitor Research Talk, Vector Institute
Rethinking Human Feedback: A Regret Minimization Perspective on Preference Learning |
|
Apr 2026 — SNU AI Summit, Seoul National University
Policy-labeled Preference Learning: Is Preference Enough for RLHF? |
|
May 2025 — LG AI Research Seminar, LG AI Research
Policy Optimization with Process Score in LRMs |
|
Dec 2024 — LG AI Research Seminar, LG AI Research
Policy-labeled Preference Learning: Is Preference Enough for RLHF? |
|
Aug 2023 — LG Tech Talk, LG AI Research
Pitfall of Optimism: Distributional Reinforcement Learning with Randomized Risk Criterion |
|
May 2023 — AIIS Spring Retreat Program, Seoul National University
Pitfall of Optimism: Distributional Reinforcement Learning with Randomized Risk Criterion |
Academic Services |
Conference Reviewer
|
|
Design and source code from Jon Barron's website |